ABSTRACT
Computer network, often simply referred to as a network, is a collection of computers and devices interconnected by communications channels that facilitate communications among users and allows users to share resources. Networks may be classified according to a wide variety of characteristics. A computer network allows sharing of resources and information among interconnected devices. A server computer that link to other computers together. They often provide essential services across a network, either to private users inside a large organization or to public users via the internet. Linux, really a child of the Internet, offers all the necessary networking tools and features for integration into all types of network structures. UNIX as a server-oriented operating system, it has followed that as Linux has evolved and been developed further, it is increasingly also being used as a server operating system, particularly for smaller networks. In this thesis examines how buildup better client server setup and configure Linux platform that overcome the existing system problem. The thesis will look at the various approaches and enabling tools suitable for this purpose, and develop the most suitable.
Introduction
The origins of Linux lie with the development of the UNIX operating system. Due to the origins of UNIX as a server-oriented operating system, it has followed that as Linux has evolved and been developed further, it is increasingly also being used as a server operating system, particularly for smaller networks. However, in recent years as Microsoft has moved into the server market, Linux is increasingly losing out to Windows in terms of user-friendliness, in part due to the non-graphical way in which many of the services are set up and configured. We will start with an overview of Computer networking, client server network and about Linux. We will discuss advantages of this system. We will talk about Linux verses windows.
What is Computer Networking?
Computer networking is the engineering discipline concerned with the communication between computer systems or devices. A computer network is any set of computers or devices connected to each other with the ability to exchange data. Examples of different network methods are:
- Local area network (LAN), which is usually a small network constrained to a small geographic area. An example of a LAN would be a computer network within a building.
- Metropolitan area network (MAN), which is used for medium size area. Examples for a city or a state.
- Wide area network (WAN) that is usually a larger network that covers a large geographic area.
- Wireless LANs and WANs (WLAN & WWAN) are the wireless equivalent of the LAN and WAN.
All networks are interconnected to allow communication with a variety of different kinds of media, including twisted-pair copper wire cable, coaxial cable, optical fiber, power lines and various wireless technologies.
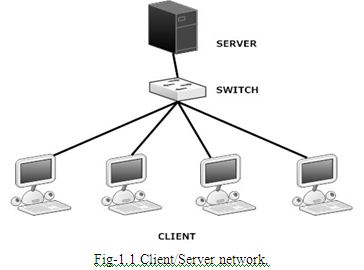
Client/Server Network
Client/server network operating systems allow the network to centralize functions and applications in one or more dedicated servers. The servers become the heart of the system, providing access to resources and providing security. Individual workstations (clients) have access to the resources available on the servers.
Advantages of a client-server network:
- Centralized – Resources and data security are controlled through the server.
- Scalability – Any or all elements can be replaced individually as needs increase.
- Flexibility – New technology can be easily integrated into system.
- Interoperability – All components (client/network/server) work together.
- Accessibility – Server can be accessed remotely and across multiple platforms.
The Client/Server network following activities as Fig-1.1 below:
What is Linux
Linux is a UNIX-like computer operating system family that uses the Linux kernel. A Linux system which includes system utilities and libraries from the GNU Project is sometimes referred to as GNU/Linux [1].
Initially developed and used primarily by individual enthusiasts on personal computers, Linux has since gained the support of corporations such as IBM, Sun, Microsystems, Hewlett-Packard, Novell, Inc and has risen to prominence as an operating system for servers. Linux has been more widely ported to different computing platforms than any other operating system. It is used in devices ranging from supercomputers to mobile phones, and has a foothold in the personal computer and business desktop markets.
Linux is a prominent example of the free software and open source development. Its underlying source code is available for anyone to use, modify, and redistribute freely and in some instances the entire operating system consists of free/open source software.
How to Use Linux
At some level all operating systems are the same, but in some ways that will matter to you, Linux is very different from the others. The most important outcomes of the community-based and non-Proprietary models, for you, that you will notice and that will make a difference in how you use the computer, are:
- There is one way to install software that works the same for all software, and all the software you might ever want to install is all accessible, searchable, findable, and installable from one single fairly easy to use application.
- There is no trial ware or advertising or wanton popups telling you to buy something.
- There are no end user agreements to click on, although the software is all licensed (you need to know nothing about this).
- You will not have a situation arise where you have to agree to a new end user license for software you’ve already installed.
- It is trivially easy to install software.
- It is trivially easy to remove software.
- When you remove software, it is really gone.
- You can install or remove software without having to close down other software.
- You will never have to reboot for new software to work, unless it is part of the operating system itself (and then you may or may not have to log out and back in or reboot).
- A bug is a bug, and people generally admit that it is a bug. And they tend to get fixed fast in the mainstream applications. (Compared to proprietary software, anyway.)
Linux itself is fundamentally different from Windows in several ways that will also matter to you.
- Linux is case sensitive. So, a file called mystuff is different from a file called MyStuff.
- Linux uses “extensions” (like the ‘.doc’ in mydoc.doc) but does not require them. Actually, it doesn’t use them at all, but a lot of software that runs on Linux assumes you are accustomed to extensions.
- You will see very few confirmations in Linux. When you select a file and delete it, it is gone. You do not have to have a conversation with the computer via arcane dialog boxes (note: in Gnome, a “deleted” file is put into the “trash”).
- Different “applications” (called “Processes” in Linux) run very independently from each other. Your browser can’t crash your spreadsheet, and your spreadsheet can’t crash your word processor, or at least, it is very unlikely for that to happen.
- The operating system itself is lean and mean. It uses few computer resources (memory and stuff) and is crispy, not sluggish.
- You don’t have to (and in fact can’t) “defrag” the hard drive, because the file systems that Linux use are designed to not break themselves over time.
“Wipe the drive and reinstall the system” is possible, sometimes it is done, but it is never necessary. It is only done by people who screw up their computer and are former Windows users and don’t know any better.
Definition of Linux Server Systems
Due to the origins of UNIX as a server-oriented operating system, it has followed that as Linux has evolved and been developed further, it is increasingly also being used as a server operating system, particularly for smaller networks. However, in recent years as Microsoft has moved into the server market, Linux is increasingly losing out to Windows in terms of user-friendliness, in part due to the non-graphical way in which many of the services are set up and configured.
The most important functions of a server are:-
v DNS (Domain Name Service)
v Mail Server (Send Mail)
v FTP (File Transfer Protocol )
v NFS (Network File System)
v SMB (Sever Message Block)
v DHCP (Dynamic Host Configuration Protocol)
v Apache Web Server
Advantages of Linux Server System
Low-cost:
There is no need to spend time and huge amount money to obtain licenses since Linux and much of its software come with the GNU General Public License. There is no need to worry about any software’s that you use in Linux.
Stability:
Linux has high stability compared with other operating systems. There is no need to reboot the Linux system to maintain performance levels. Rarely it freeze up or slow down. It has continuous up-times of hundreds of days or more.
Performance:
Linux provides high performance on various networks. It has the ability to handle large numbers of users simultaneously.
Networking:
Linux provides a strong support for network functionality; client and server systems can be easily set up on any computer running Linux. It can perform tasks like network backup faster than other operating systems.
Flexibility:
Linux is very flexible. Linux can be used for high performance server applications, desktop applications, and embedded systems. You can install only the needed components for a particular use. You can also restrict the use of specific computers.
Compatibility:
It runs all common UNIX software packages and can process all common file formats.
Wider Choice:
There are a large number of Linux distributions which gives you a wider choice. Each organization develops and support different distribution. You can pick the one you like best; the core functions are the same.
Fast and easy installation:
Linux distributions come with user-friendly installation.
Better use of hard disk:
Linux uses its resources well enough even when the hard disk is almost full.
Multitasking:
Linux is a multitasking operating system. It can handle many things at the same time.
Security:
Linux is one of the most secure operating systems. File ownership and permissions make Linux more secure.
Open source:
Linux is an Open source operating systems. You can easily get the source code for Linux and edit it to develop your personal operating system.
Today, Linux is widely used for both basic home and office uses. It is the main operating system used for high performance business and in web servers. Linux has made a high impact in this world.
Usage of Linux
Linux is used on a wide variety of machines for a wide variety of purposes. Desktop Linux distributions typically feature a user interface comparable with that of Microsoft Windows and Mac OS X, through migrating users usually have to switch to alternative application software, and there may be a lack of commercial quality software in certain application domains, such as computer gaming, desktop publishing, and professional audio. However, there exit high quality replacements for general-purpose desktop software, word processors, email clients, and web browsers. Additionally, a growing number of proprietary software vendors are supporting Linux.
Programming
Most Linux distributions support a wide array of programming language, Core system software such as libraries and basic utilities are usually written in C. Enterprise software is often written in C++, Java, Perl, or Python. The most Common collection of utilities for building both Linux applications and operating system programs is found within the GNU tool chain, which includes the GNU Complier Collection. (GCC). Amongst others, GCC provides compilers for C, C++, Java, and Fortran. The Linux kernel itself is written to be compiled with GCC.
Most distributions also include support for Perl, Python and other dynamic languages. Less common, but still well-supported, are C# via the Mono project, Scheme and Ruby. The two main widget toolkits used for contemporary GUT programming are Qt and the Gimp Toolkit, known as GTK. Both support a wide variety of languages. There are a number of integrated development environments available including MonoDevelop, KDevelop, Anjuta, Netbeans, and Eclipse while the traditional editors Emacs and Vim remain popular.
As well as these free and open source options, there are proprietary compilers and tools available from a range of companies such as the Intel C Compiler, Path Scale, Micro Focus COBOL Franz Inc and the Portland Group.
Enterprise usage
Linux is also used in some corporate environments as the desktop platform for its employees, with commercially available solutions including Red Hat Enterprise Linux, SIJSE Linux Enterprise Desktop and Linspire. Several government organizations have stared the switch to using Linux.
Server usage
Historically, Linux has mainly been used as a server operating system. This is due to its relative stability and long uptimes, and the fact that desktop software with a graphical user interface is often unneeded. Enterprise and non-enterprise Linux distributions may be found running on servers. Linux is the cornerstone of the LAMP server-software combination (Linux, Apache, MySQL, and Perl/PHP/Python) which has achieved popularity among developers, and which is one of the more common platforms for website hosting.
Embedded System
Due to its low cost and its high configurability, an embedded Linux is often used in embedded systems such as television set-top boxes, mobile phone and handled devices. Linux has become a major competitor to the proprietary Symbian OS found in many mobile phones and it is an alternative to the dominant Windows CE and Palm OS, operating systems on handheld devices. The popi TiVo digital video recorder uses a customized version of Linux Several network firewall and router standalone products, including several from Linksys, use Linux internally, using its advanced fire walling and routing capabilities.
Gaming
Although gaming under Linux is traditionally considered inferior to gaming under Windows or Mac OS X, due to the reluctance of game development companies to support an operating system with relatively small desktop market share, there are still a large number of games available. Prominent examples of open source games include Nethack, and Battle for Wesnoth. There are also emulators for playing binary game ROMs, which include ZSNES and Frotz. Some Windows games may be played using Wine or Cedega, and old MS-DOS gaines can be played with DOSBox. Finally, there are games such as Quake which have an open source engine that runs under Linux, and can be used to play the full game provided non-free data files are present. Library support for Linux gaming is provided by Simple Direct Media Layer, a wrapper around OpenGL, audio libraries, and input devices. NVidia and ATI have provided kernel modules that allow for most features of their graphics cards to be used under Linux. Linux also runs on several game consoles, including the X-Box, PlayStation, and Gamecube. This has allowed game developers without an expensive proprietary game development kit to target console hardware.
Education
In technical disciplines at universities and research centers worldwide, Linux is often the platform of choice. This is due to several factors, including that Linux is available free of charge and includes a large body of free/open source software. To some extent, technical competence of contributor, as is stability, maintainability, and upgradability. IBM ran an advertising campaign entitled “Linux is Education” featuring a young boy who was supposed to be “Linux”. The one Laptop per Child project, a campaign to distribute laptop computers to millions of children in the developing world, also uses a Linux operating system.
Linux vs. Windows
Linux is an open-source Operating System. People can change codes and add programs to Linux OS which will help use your computer better. Linux evolved as a reaction to the monopoly position of windows. You can’t change any code for windows OS. You can’t even see which processes do what and build your own extension. Linux wants the programmers to extend and redesign its OS. Linux user’s can edit its OS and design new OS.
All flavors of Windows come from Microsoft. Linux come from different companies like LIndows, Lycoris, Red Hat, SuSe, Mandrake, Knopping, Fedora and Slackware.
Linux is customizable but Windows is not. For example, NASlite is a version of Linux that runs off a single floppy disk and converts an old computer into a file server. This ultra small edition of Linux is capable of networking, file sharing and being a web server.
Linux is freely available for desktop or home use but Windows is expensive. For server use, Linux is cheap compared to Windows. Microsoft allows a single copy of Windows to be used on one computer. You can run Linux on any number of computers. Linux has high security. You have to log on to Linux with a user id and password. You can login as root or as normal user. The root has full privilege. Linux has a reputation for fewer bugs than Windows. Windows must boot from a primary partition. Linux can boot from either a primary partition or a logical partition inside an extended partition. Windows must boot from the first hard disk. Linux can boot from any hard disk in the computer.
Windows uses a hidden file for its swap file. Typically this file resides in the same partition as the OS (advanced users can opt to put the file in another partition). Linux uses a dedicated partition for its swap file.
Windows separates directories with a back slash while Linux uses a normal forward slash. Windows file names are not case sensitive. Linux file names are case sensitive. For example “abc” and “aBC” are different files in Linux, whereas in Windows it would refer to the same file.
Windows and Linux have different concepts for their file hierarchy. Windows uses a volume-based file hierarchy while Linux uses a unified scheme. Windows uses letters of the alphabet to represent different devices and different hard disk partitions. eg: c: , d: , e: etc.. While in linux ” / ” is the main directory. Linux and windows support the concept of hidden files. In Linux hidden files begin with ” . “, eg: .filename
In Linux each user will have a home directory and all his files will be save under it while in windows the user saves his files anywhere in the drive. This makes difficult to have backup for his contents. In Linux it’s easy to have backups.
Outline of the thesis paper:
[Chapter 2]: Describes about the Existing topology, proposed topology plan, resource collection, and operating system.
[Chapter 3]: Describes about the some kind of server such as Proxy Server, DNS Server, Mail Server, FTP Server, Samba Server, DHCP Server, and Apache Server.
Planning, Designing and Installation
Existing Topology
Existing network of our project area is a client server network with Windows platform. In our existing network there is a multiple server in individual machine that need to high configuration CPU so this is more expensive. Security lacking is present in to this network and Maintenance of this network is so difficult. Virus can affect windows network easily. The existing topology plan on the following activities as Fig-2.1 below:
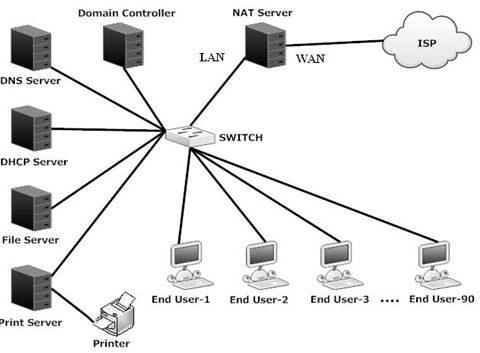
Topology plan
Our proposed network is a client-server network with Linux platform. The client–server model of computing is a distributed application structure that partitions tasks or workloads between the providers of a resource or service, called servers, and service requesters, called clients. Often clients and servers communicate over a computer network on separate hardware, but both client and server may reside in the same system. A server machine is a host that is running one or more server programs which share their resources with clients. A client does not share any of its resources, but requests a server’s content or service function. Clients therefore initiate communication sessions with servers which await incoming requests.
The client–server characteristic describes the relationship of cooperating programs in an application. The server component provides a function or service to one or many clients, which initiate requests for such services.
We need to Network Planning, Designing and Resource Collection before implementation. The topology diagram should demonstrate main internet connectivity to client end. All equipment and setup depend on our Network topology design.
Proxy Server (Squid): Squid is a widely-used proxy cache for Linux and UNIX platforms. Squid acts as a proxy cache.To translate private IP address into public IP address so that our end users can use the internet connection.
File Server: In file server there is a central storage, where all important files are stored. We can backup and restore our files through file server..
DNS Server: We want to use our own DNS server for our network. Also DHCP server lease IP address to our end users, through DNS server the communication can be made by respective PC/Server name.
Mail Server: A mail server is an application that receives incoming e-mail from local users and remote senders and forwards outgoing e-mail for delivery.
DHCP Server: It is difficult to assign IP address manually in to a large network. So we use DHCP server to assign IP address automatically to the end user.
Samba Server: Samba is a networking tool that enables Linux to participate in Windows networks. There are two parts to Samba, one being the server which shares out files and printers for other PC’s to use, and the other being the client utilities, which allow Linux to access files and printers on other Windows/Samba PCs.
Apache Server: The Apache HTTP Server, commonly referred to as Apache is web server software notable for playing a key role in the initial growth of the World Wide Web.
The main internet connection from ISP is connected in the WAN interface of our Squid server. We want use UTP cable to connect our internal network. In the LAN interface of Squid server a switch is connected by straight through cable. All servers and end users are connected to the switch by straight through cable.
Resource Collection
For designing a network resources are very much necessary. In this section we discuss about resources.
Public IP Address
We need public IP address into our network for internet connectivity. To obtain public IP address we contact with an ISP. ISP gives us one public IP address and 1Mbps bandwidth with the following configuration for our WAN interface:
- IP Address=114.31.25.82
- Default Gateway=114.31.25.81
- Subnet Mask=255.255.255.252
- Primary DNS=114.31.0.66
- Alternate DNS=4.2.2.2
Private IP Address
Basic planning of this project depends on architect of IP addresses. Now our main target of requirements is to find out how many private IP address is need? We need 96 host assignable IP addresses for our end user and servers. As for this, we take a Class C network number of 192.168.1.0, it simply enough 1 subnet regarding the project requirements. So we get easily subnet mask, Total IP and usable IP.
Under the all circumstances, summary table of IP Network 192.168.1.0/24:
Table 2.1: Summary Table of IP address
| Total Network | 1 |
| Subnet Mask | 255.255.255.0 |
| Total IP per Network | 256 |
| Host assignable IP per Network | 256 – 2 = 254 |
The chart for usable subnets of IP address 192.168.1.0/24 will be:
Operating System
An operating system (OS) is a program that allows you to interact with the computer all of the software and hardware on your computer. How? Basically, there are two ways: 1. with a command-line operating system (e.g., DOS), you type a text command and the computer responds according to that command. 2. with a graphical user interface (GUI) operating system (e.g., Windows), you interact with the computer through a graphical interface with pictures and buttons by using the mouse and keyboard. With UNIX you have in general the option of using either command-lines (more control and flexibility) or GUIs (easier). [4] Operating System placement on computer usage which is shown in Fig-2.2 is given below:
Choosing the right OS for Server configuration
It is very important to choice a good operating system and stable system. Server performance depends on Operating system.All commercial operating system common features. But feature are not important, important is stability.
Linux as Server OS
Linux is a free UNIX operating system originally created by Linux Torvaldas with the assistance of developers around the world. It is developed under the GNU GPL (General Public License) the source code for Linux is freely available to everyone. There are is no user licensing related regulatory binding.
A Linux distribution is version of the Linux operating system made especially by a company, organization or individual. The one thing they all have in common is that they use the Linux Kernel, from there on each developer will add programs tools and other applications some are dedicated to specific user while others are intended for general public.
Gnu/Linux is the name of Linux by Richard Staliman founder of the free software foundation and GNU project. They cite fact that Linux could not have come into being without tools from the GNU project. Though this is true, use and custom has favored Linux over GNU/Linux in the contributions of the free software foundation.
Installation Preparation
Before going to install an operating system like Linux need to become content with few term and topics as:
Hardware Compatibility
The hardware compatibility lists provide a representative list of hardware peripherals that are compatible with operating system. Each operating system has its own hardware compatibility list. It differs on operating system’s version and distribution. You need to tally your hardware with your chosen operating system’s HCL. Linux Question.org contains a good HCL for overall Linux operating system. LinuxHCL.com contains almost same type of HCL for Linux.
Minimum Hardware for Red Hat
As we have decided to demonstrate all examples in this using RedHat you need to know the minimum hardware requirement for this OS. This follows information the minimum hardware requirement necessary to successfully install RedHat Linux as:
Table 2.3: Hardware Requirements
| Hardware | Minimum Requirement
|
|
CPU | 1.Minimum Pentium class processor (or Higher). 2.Recommended for text-mode 200MHz Pentium class or better. 3. Recommended for graphical-mode 400MHz Pentium II class or better. |
| Hard Disk Space | 1.Custom Installation 475 MB 2. Server: 850 MB 3. workstation: 2.1 GB |
Software Specification
The software specification needed to execute the program is listed bellow:
Operating Systems:
- Red Hat Linux Enterprise.
Installation Media:
You can install Linux operating system form any comfortable media like CD ROM. Hard disk including all network installation method (you can install Linux from HTTP, FTP and NFS). You should check the media consistency properly before you start installation. Most of the time we find corrupted CD ROM packages, which makes unnecessary errors at installation time and eats valuable time.
Measuring Disk Space
You need measure your disk space. Disk space depends on type of installation as well as the services you will run. If you run some services, which may require a big space your storage consideration will be changed completely. It also depends on your server role. If you run your server to store huge amount of log, it will take a large hard disk space.
Disk Partition and File System
A partition is a method of dividing your hard disk into multiple sections. So that the operating system from the same disk. File system can be considered as being the directory structure on disk partition that contains all file. Most Windows user would be familiar with the analogous term “folder” and “sub-folder”. Wheals Linux users would be familiar with the terms “directory” and “sub-directory”. You need to know detail about hard disk partition and file system. A good partition can give servers a long life.
Installation OS
Now choice Red Hat Linux OS and install the OS step-by-step
1) Setting up BIOS Boot Sequence: Configure your BIOS CDROM so that system boots from CDROM.
2) Starting Installation: Insert Red Hat Linux CD into CDROM and boot the machine.
3) Booting Installation Program: After a short delay a screen containing the boot prompt should appear. The screen contains information on a verity of boot option. To access a help screen, press the appropriate function key as listed in the line at the bottom of the screen. Once you see the boot prompt the installation program will automatically begin if you take no action within the first minute. Now start a text mode installation.
4) Welcome to Red Hat Linux: After the initial booting “welcome screen” will appear. The few option will appear like language selection, keyboard selection, and mouse configuration one after another. Choose your option and select.
5) Choosing to update or install: Now you will be asked to select Install/Update. Select install.
6) Installation Type: Choose server option from this dialog.
7) Boot Partition: Use disk druid to partition your hard disk.Do it carefully, make all partition according to previous plan. If you do not know how to operate Disk Druid properly please see supplied document on installation.
8) Boot Loader Configuration: Now select a place to install a boot loader select “LILO” or “GRUB” loader as you like. Install it into MBR.
9) Firewall Configuration: Select no firewall because firewall creates manually.
10) Language Support selection: Install and support multiple languages for use in your system.
11) Time Zone Configuration: Set time zone by selecting our computer’s physical location or by specifying your time zone’s offset from Universal Time Coordinated select as per we need.
12) Root Password: Set a password for our root user.
13) Authentication Configuration: If we do not know what we are going to do, keep it as usual and choose next.
14) Package Group selection: Unless you choose a custom installation the installation program will automatically most useful package for us. Choice more package if we need.
15) Selecting Individual Package: we can use this option for more customized package selection.
16) Preparation to install: we should now see a screen preparing you for the installation of Redhat Linux. Start back and relax.
17) Installing Package: At this point there is nothing left for you to do until the entire packages are installed.
18) Boot Diskette Creation: At this point you will be asked to create a boot disk if we need.
19) Complete Installation: Now complete installation and reboot system. Remove installation media system and ready to use.
Defining Several Server System
Proxy Server: Squid
Squid is a widely-used proxy cache for Linux and UNIX platforms. The chapter discusses its configuration, the settings required to get it running, how to configure the system to do transparent proxying, how to gather statistics about the cache’s use with the help of programs like Calamaris and cachemgr, and how to filter web contents with squidGuard.[5] Squid Server working procedure which is shown in Fig-3.1 is given below:
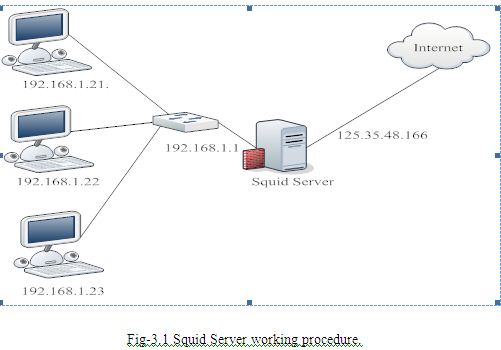
Squid as Proxy Cache
Squid acts as a proxy cache. It behaves like an agent that receives requests from clients, in this case web browsers, and passes them to the specified server. When the requested objects arrive at the agent, it stores a copy in a disk cache.
The main advantage of this becomes obvious as soon as different clients request the same objects: these are served directly from the disk cache, much faster than obtaining them from the Internet. At the same time, this results in less network traffic and thus saves bandwidth.
Squid is not a generic proxy. It proxies normally only HTTP connections. It does also support the protocols FTP, Gopher, SSL, and WAIS, but it does not support other Internet protocols, such as Real Audio, news, or video conferencing. Because Squid only supports the UDP protocol to provide communication between different caches, many other multimedia programs are not supported.
Some Facts about Proxy Caches
In this section we discus some facts about proxy caches.
Squid and Security
It is also possible to use Squid together with a firewall to secure internal networks from the outside using a proxy cache. The firewall denies all clients access to external services except Squid. All web connections must be established by way of the proxy.
If the firewall configuration includes a DMZ, the proxy should operate within this zone. In this case, it is important that all computers in the DMZ send their log files to hosts inside the secure network.
Multiple Caches
Several proxies can be configured in such a way that objects can be exchanged between them, reducing the total system load and increasing the chances of finding an object already existing in the local network. It is also possible to configure cache hierarchies, so a cache is able to forward object requests to sibling caches or to a parent cache – causing it to get objects from another cache in the local network or directly from the source.
Choosing the appropriate topology for the cache hierarchy is very important, because is not desirable to increase the overall traffic on the network. For a very large network, it would make sense to configure a proxy server for every subnetwork and connect them to a parent proxy, which in turn is connected to the proxy cache of the ISP.
All this communication is handled by ICP (Internet Cache Protocol) running on top of the UDP protocol. Data transfers between caches are handled using HTTP (Hyper Text Transmission Protocol) based on TCP.
To find the most appropriate server from which to get the objects, one cache sends an ICP request to all sibling proxies. These answer the requests via ICP responses with a HIT code if the object was detected or a MISS if it was not. If multiple HIT responses were found, the proxy server decides from which server to download, depending on factors such as which cache sent the fastest answer or which one is closer. If no satisfactory responses are received, the request is sent to the parent cache.
Caching Internet Objects
Not all objects available in the network are static. There are a lot of dynamically generated CGI pages, visitor counters, and encrypted SSL content documents. Objects like this are not cached because they change each time they are accessed.
The question remains as to how long all the other objects stored in the cache should stay there. To determine this, all objects in the cache are assigned one of various possible states.
Web and proxy servers find out the status of an object by adding headers to these objects, such as “Last modified” or “Expires” and the corresponding date. Other headers specifying that objects must not be cached are used as well.
Objects in the cache are normally replaced, due to a lack of free hard disk space, using algorithms such as LRU (Last Recently Used). Basically this means that the proxy expunges the objects that have not been requested for the longest time.
System Requirements
The most important thing is to determine the maximum load the system must bear. It is, therefore, important to pay more attention to the load peaks, because these might be more than four times the day’s average. When in doubt, it would be better to overestimate the system’s requirements, because having Squid working close to the limit of its capabilities could lead to a severe loss in the quality of the service. The following sections point to the system factors in order of significance.
Hard Disks
Speed plays an important role in the caching process, so this factor deserves special attention. For hard disks, this parameter is described as random seek time, measured in milliseconds. Because the data blocks that Squid reads from or writes to the hard disk will tend to be rather small, the seek time of the hard disk is more important than its data throughput. For the purposes of a proxy, hard disks with high rotation speeds are probably the better choice, because they allow the read-write head to be positioned in the required spot much quicker. Fast SCSI hard disks nowadays have a seek time of under 4 milliseconds.
One possibility to speed up the system is to use a number of disks concurrently or to employ striping RAID arrays.
Size of the Disk Cache
In a small cache, the probability of a HIT (finding the requested object already located there) is small, because the cache is easily filled so the less requested objects are replaced by newer ones. On the other hand, if, for example, 1 GB is available for the cache and the users only surf 10 MB a day, it would take more than one hundred days to fill the cache.
The easiest way to determine the needed cache size is to consider the maximum transfer rate of the connection. With a 1 Mbit/s connection, the maximum transfer rate is 125 KB/s. If all this traffic ends up in the cache, in one hour it would add up to 450 MB and, assuming that all this traffic is generated in only eight working hours, it would reach 3.6 GB in one day. Because the connection is normally not used to its upper volume limit, it can be assumed that the total data volume handled by the cache is approximately 2 GB. This is why 2 GB of disk space is required in the example for Squid to keep one day’s worth of browsed data cached.
RAM
The amount of memory required by Squid directly correlates to the number of objects in the cache. Squid also stores cache object references and frequently requested objects in the main memory to speed up retrieval of this data. Random access memory is much faster than a hard disk.
In addition to that, there is other data that Squid needs to keep in memory, such as a table with all the IP addresses handled, an exact domain name cache, the most frequently requested objects, access control lists, buffers, and more.
It is very important to have sufficient memory for the Squid process, because system performance is dramatically reduced if it must be swapped to disk. The cachemgr.cgi tool can be used for the cache memory management.
CPU
Squid is not a program that requires intensive CPU usage. The load of the processor is only increased while the contents of the cache are loaded or checked. Using a multiprocessor machine does not increase the performance of the system. To increase efficiency, it is better to buy faster disks or add more memory.
Starting Squid
Squid is already preconfigured in SUSE LINUX, so you can start it easily right after installation. A prerequisite for a smooth start is an already configured network, at least one name server, and Internet access. Problems can arise if a dial-up connection is used with a dynamic DNS configuration. In cases such as this, at least the name server should be clearly entered, because Squid does not start if it does not detect a DNS server in /etc/resolv.conf.
To start Squid, enter rcsquid start at the command line as root. For the initial start-up, the directory structure must first be defined in /var/squid/cache. This is done by the start script /etc/init.d/squid automatically and can take a few seconds or even minutes. If done appears to the right in green, Squid has been successfully loaded. Test Squid’s functionality on the local system by entering localhost and Port 3128 as proxy in the browser.
To allow all users to access Squid and, through it, the Internet, change the entry in the configuration file /etc/squid/squid.conf from http_access deny all to http_access allow all. However, in doing so, consider that Squid is made completely accessible to anyone by this action. Therefore, define ACLs that control access to the proxy.
If you have made changes in the configuration file /etc/squid/squid.conf, tell Squid to load the changed file by entering rcsquid reload. Alternatively, do a complete restart of Squid with rcsquid restart.
Another important command is rcsquid status, which allows you to determine whether the proxy is running. Finally, the command rcsquid stop causes Squid to shut down. This can take a while, because Squid waits up to half a minute (shutdown_lifetime option in /etc/squid/squid.conf) before dropping the connections to the clients and writing its data to the disk.
If Squid dies after a short period of time even though it was started successfully, check whether there is a faulty name server entry or whether the /etc/resolv.conf file is missing. The cause of a start failure is logged by Squid in the /var/squid/logs/cache.log file. If Squid should be loaded automatically when the system boots, use the YaST runlevel editor to activate Squid for the desired runlevels.
An uninstall of Squid does not remove the cache or the log files. To remove these, delete the /var/cache/squid directory manually.
Local DNS Server
Setting up a local DNS server, such as BIND9, makes sense even if the server does not manage its own domain. It then simply acts as a caching-only DNS and is also able to resolve DNS requests via the root name servers without requiring any special configuration. If you enter the local DNS server in the /etc/resolv.conf file with the IP address 127.0.0.1 for localhost, Squid should always find a valid name server when it starts. For this to work, it is sufficient just to start the BIND server after installing the corresponding package. The name server of the provider should be entered in the configuration file /etc/named.conf under forwarders along with its IP address. However, if you have a firewall running, you need to make sure that DNS requests can pass it.
The Configuration File /etc/squid/squid.conf
All Squid proxy server settings are made in the /etc/squid/squid.conf file. To start Squid for the first time, no changes are necessary in this file, but external clients are initially denied access. The proxy must be made available for the localhost, usually with 3128 as port. The options are extensive and therefore provided with ample documentation and examples in the preinstalled /etc/squid/squid.conf file. Nearly all entries begin with a # sign (the lines are commented) and the relevant specifications can be found at the end of the line. The given values almost always correlate with the default values, so removing the comment signs without changing any of the parameters actually has little effect in most cases. It is better to leave the sample as it is and reinsert the options along with the modified parameters in the line below. In this way, easily interpret the default values and the changes.
Domain Name System
The Domain Name System is a standard technology for managing the names of Web sites and other Internet domains. The DNS is used to resolve human-readable hostnames, such as www.redhat.com, into machine-readable IP addresses, such as 63.208.196.66. DNS also provides other information about domain names, such as mail services. The DNS service will be install so that email clients can resolve DNS domains through this server.
DNS Domains
Everyone in the world has a first name and a last, or family, name. The same thing is true in the DNS world: A family of Web sites can be loosely described a domain. For example, the domain digitalworldit.com has a number of children, such as www.digitalworldit.com and mail.digitalworldit.com for the Web and mail servers, respectively.
Important Files
v The /etc/resolv.conf File
DNS clients (servers not running BIND) use the /etc/resolv.conf file to determine both
Table 3.1 Keywords In /etc/resolv.conf
| Keyword | Value |
| Nameserver | IP address of your DNS nameserver. There should be only one entry per “nameserver” keyword. If there is more than one nameserver, you’ll need to have multiple “nameserver” lines. |
| Domain | The local domain name to be used by default. If the server is bigboy.my-web-site.org, then the entry would just be my-web-site.org |
| Search | If you refer to another server just by its name without the domain added on, DNS on your client will append the server name to each domain in this list and do an DNS lookup on each to get the remote servers’ IP address. Domain by only their servername without having to specify the domain. The domains in this list must separated by spaces. |
the location of their DNS server and the domains to which they belong. The file generally has two columns; the first contains a keyword, and the second contains the desired values separated by commas. See Table 3.1 for a list of keywords.
Take a look at a sample configuration in which the client server’s main domain is my-site.com, but it also is a member of domains my-site.net and my-site.org, which should be searched for shorthand references to other servers. Two name servers, 192.168.1.100 and 192.168.1.102, provide DNS name resolution:
search my-site.com my-site.net my-site.org
nameserver 192.168.1.100
nameserver 192.168.1.102
The first domain listed after the search directive must be the home domain of your network, in this case my-site.com. Placing a domain and search entry in the /etc/resolv.conf is redundant, therefore
v Named.conf File
The /etc/named.conf file contains the main DNS configuration and tells BIND where to find the configuration, or zone files for each domain you own. This file usually has two zone areas:
- Forward zone file definitions list files to map domains to IP addresses.
- Reverse zone file definitions list files to map IP addresses to domains.
Some versions of BIND will come with a /etc/named.conf file configured to work as a caching nameserver which can be converted to an authoritative nameserver by adding the correct references to your zone files. Please proceed to the next section if this is the case with your version of BIND.
In other cases the named.conf configuration file may be hard to find. Some versions of Linux install BIND as a default caching nameserver using a file names /etc/named.caching-nameserver.conf for its configuration. In such cases BIND becomes an authoritative nameserver when a correctly configured /etc/named.conf file is created. Fortunately BIND comes with samples of all the primary files you need. Table 18.3 explains their names and purpose in more detail.
Table-3.2 Primary BIND Configuration Files
File | Description |
| /etc/named.conf | The main configuration file that lists the location of all your domain’s zone files |
| /etc/named.rfc1912.zones | Base configuration file for a caching name server. |
| /var/named/named.ca | A list of the 13 root authoritative DNS servers. |
The first task is to make sure your DNS server will listening of requests on all the required network interfaces. The options section of named.conf may be configured to listen exclusively on its internal hidden localhost interface with an IP address of 127.0.0.1 as we see in this example.
# File: /etc/named.conf
options {listen-on port 53 { 127.0.0.1 };};
If other devices are going to rely on your server for queries, then you’ll need to either change this or add a selected number of IP addresses on your server. In this example, we allow queries on any interface.
listen-on port 53 { any; };
In this example, we allow queries on localhost and address 192.168.1.100.
listen-on port 53 { 127.0.0.1; 192.168.1.100; };
Mail Server
Electronic mail (E-mail) is a very important part of the Internet services. Email is an important part of any Web site you create. In a home environment, a free web based email service may be sufficient, but if you are running a business, then a dedicated mail server will probably be required. In the recent years, the Internet technology has developed quickly. Owing to its convenience, speediness, cheapness and reliability, E-mail has become one of the most popular Internet services. As a matter of fact, it is now indispensable to academic and commercial communications.
Defining Internet E-Mail
Internet E-mail is similar to the ordinary post letter. Each E-mail user has a “mailbox”. If you want to send a mail to someone, you need know his mailbox address. The E-mail address is composed of two parts: the user name and the post office name, with a “@” between them. For example, “jdx@cic.tsinghua.edu.cn” is an E-mail address, in which “jdx” is the user name while “cic.tsinghua.edu.cn” the post office name. In fact the post office in E-mail system is usually an Internet host, which is often called mail server, and a mailbox is often a file in this host whose name is the same as the user name.
FTP Server
FTP (File Transfer Protocol) is the generic term for a group of computer programs aimed at facilitating the transfer of files or data from one computer to another. It originated in the Massachusetts Institute of Technology (MIT) in the early 1970s when mainframes, dumb terminals and time-sharing were the standard.
l FTP is based on the client-server model of communication between computers: one computer runs a server program that makes information available to other computers.
l The other computers run client programs that request information and receive replies from the server.
l To access an FTP server, users must be able to connect to the Internet or an intranet (via a modem or local area network) with an FTP client program.
FTP relies on a pair of TCP ports to get the job done. It operates in two connection channels as I’ll explain:
FTP Control Channel, TCP Port 21: All commands you send and the ftp server’s responses to those commands will go over the control connection, but any data sent back (such as “ls” directory lists or actual file data in either direction) will go over the data connection.
FTP Data Channel, TCP Port 20: This port is used for all subsequent data transfers between the client and server.
Types of File Servers
A file server may be dedicated or non-dedicated. A dedicated server is generally designed specifically for use as a file server, with workstations attached for reading and writing files and databases. File servers may also be categorized by the method of access: Internet file servers are frequently accessed by File Transfer Protocol (FTP) or by HTTP (but are different from web servers that often provide dynamic web content in addition to static files).[6]
Design of File Servers
In modern businesses the design of file servers is complicated by competing demands for storage space, access speed, recoverability, ease of administration, security, and budget. This is further complicated by a constantly changing environment, where new hardware and technology rapidly obsoletes old equipment, and yet must seamlessly come online in a fashion compatible with the older machinery. To manage throughput, peak loads, and response time, vendors may utilize queuing theory to model how the combination of hardware and software will respond over various levels of demand. Servers may also employ dynamic load balancing scheme to distribute requests across various pieces of hardware.
Storage
Since the crucial function of a file server is storage, technology has been developed to operate multiple disk drives together as a team, forming a disk array. A disk array typically has cache (temporary memory storage that is faster than the magnetic disks), as well as advanced functions like RAID and storage virtualization. Typically disk arrays increase level of availability by using redundant components other than RAID, such as power supplies. Disk arrays may be consolidated or virtualized in a storage area network (SAN).
Samba Server
SMB stands for – Server Message Block. Samba is a suit of programs that work to allow Windows® clients to access a server’s file space and printers via the SMB protocols. Linux files can be shared in several ways. The first is via NFS and the second is via SAMBA. When sharing files to Windows clients, use SAMBA. Operating systems that support this natively include Windows NT, OS/2, and Linux. Samba is an Open Source/Free Software suite that provides seamless file and print services to SMB/CIFS clients. Samba is freely available, unlike other SMB/CIFS implementations, and allows for interoperability between Linux/Unix servers and Windows-based clients.
Samba Service
a) File and Printer Sharing from Linux to Windows
b) Uses SMB Daemon
c) service SMB start/stop/restart
Samba services are implemented as two daemons:
- smbd, which provides the file and printer sharing services, and
- nmbd, which provides the NetBIOS-to-IP-address name service. NetBIOS over TCP/IP requires some method for mapping NetBIOS computer names to the IP addresses of a TCP/IP network.
The Samba Configuration File Format
The /etc/samba/smb.conf file is the main configuration file you’ll need to edit. It is split into five major sections, which Table-3.4 outlines:
Table-3.3: File Format – smb.conf
| Section | Description |
| [global] | General Samba configuration parameters |
| [printers] | Used for configuring printers Used for configuring printers |
| [homes] | Defines treatment of user logins |
| [netlogon] | A share for storing logon scripts. (Not created by default.) |
| [profile] | A share for storing domain logon information such as “favorites” and desktop icons. (Not created by default.) |
You can edit this file by hand, or more simply through Samba’s SWAT web interface.
Dynamic Host Configuration Protocol
The purpose of the dynamic host configuration protocol (DHCP) is to assign network settings centrally from a server rather than configuring them locally on each and every workstation. A client configured to use DHCP does not have control over its own static address. It is enabled to configure itself completely and automatically according to directions from the server. A DHCP server supplies not only the IP address and the net mask, but also the host name, domain name, gateway, and name server addresses for the client to use. In addition to that, DHCP allows for a number of other parameters to be configured in a centralized way, for example, a time server from which clients may poll the current time or even a print server.
Overview
The Dynamic Host Configuration Protocol (DHCP) is an auto configuration protocol used on IP networks. Computers that are connected to IP networks must be configured before they can communicate with other computers on the network. DHCP allows a computer to be configured automatically, eliminating the need for intervention by a network administrator. It also provides a central database for keeping track of computers that have been connected to the network. This prevents two computers from accidentally being configured with the same IP address.
In the absence of DHCP, hosts may be manually configured with an IP address. Alternatively IPv6 hosts may use stateless address auto configuration to generate an IP address. IPv4 hosts may use link-local addressing to achieve limited local connectivity.
Technical Details
DHCP uses the same two ports assigned by IANA for BOOTP: UDP port 67 for sending data to the server, and UDP port 68 for data to the client. DHCP communications are connectionless in nature.
DHCP operations fall into four basic phases: IP discovery, IP lease offer, IP request, and IP lease acknowledgement.
DHCP clients and servers on the same subnet communicate via UDP broadcasts. If the client and server are on different subnets, IP discovery and IP request messages are sent via UDP broadcasts, but IP lease offer and IP lease acknowledgement messages are unicast.
DHCP Discovery
The client broadcasts messages on the physical subnet to discover available DHCP servers. Network administrators can configure a local router to forward DHCP packets to a DHCP server from a different subnet. This client-implementation creates a User Datagram Protocol (UDP) packet with the broadcast destination of 255.255.255.255 or the specific subnet broadcast address.
A DHCP client can also request its last-known IP address (in the example below, 192.168.1.100). If the client remains connected to a network for which this IP is valid, the server might grant the request. Otherwise, it depends whether the server is set up as authoritative or not. An authoritative server will deny the request, making the client ask for a new IP address immediately. A non-authoritative server simply ignores the request, leading to an implementation-dependent timeout for the client to give up on the request and ask for a new IP address.
DHCP Offer
When a DHCP server receives an IP lease request from a client, it reserves an IP address for the client and extends an IP lease offer by sending a DHCPOFFER message to the client. This message contains the client’s MAC address, the IP address that the server is offering, the subnet mask, the lease duration, and the IP address of the DHCP server making the offer.
The server determines the configuration based on the client’s hardware address as specified in the CHADDR (Client Hardware Address) field. Here the server, 192.168.1.1, specifies the IP address in the YIADDR (Your IP Address) field.
DHCP Request
A client can receive DHCP offers from multiple servers, but it will accept only one DHCP offer and broadcast a DHCP request message. Based on the Transaction ID field in the request, servers are informed whose offer the client has accepted. When other DHCP servers receive this message, they withdraw any offers that they might have made to the client and return the offered address to the pool of available addresses. The DHCP request message is broadcast, instead of being unicast to a particular DHCP server, because the DHCP client has still not received an IP address.
DHCP Acknowledgement
When the DHCP server receives the DHCPREQUEST message from the client, the configuration process enters its final phase. The acknowledgement phase involves sending a DHCPACK packet to the client. This packet includes the lease duration and any other configuration information that the client might have requested. At this point, the IP configuration process is completed.
DHCP Releasing
The client sends a request to the DHCP server to release the DHCP information and the client deactivates its IP address. As client devices usually do not know when users may unplug them from the network, the protocol does not mandate the sending of DHCP Release.
Apache: Web Server
A computer that delivers (serves up) Web pages. Every Web server has an IP address and possibly a domain name. For example, if you enter the URL http://www.pcwebopedia.com/index/ in your browser, this sends a request to the server whose domain name is pcwebopedia.com. The server then fetches the page named index/ and sends it to your browser.
Any computer can be turned into a Web server by installing server software and connecting the machine to the Internet. There are many Web server software applications, including public domain software from NCSA and Apache, and commercial packages from Microsoft, Netscape and others.
• Apache is a web server notable for playing a key role in the initial growth of the World Wide Web.
• Apache is fast, secure, and infinitely customizable.
• Since April of 1996, Apache has been the most popular HTTP server on the World Wide Web.
The Apache httpd server
ü is a powerful, flexible, HTTP/1.1 compliant web server
ü implements the latest protocols, including HTTP/1.1 (RFC2616)
ü is highly configurable and extensible with third-party modules
ü can be customised by writing ‘modules’ using the Apache module API
ü provides full source code and comes with an unrestrictive license
ü runs on Windows NT/9x, Netware 5.x and above, OS/2, and most versions of UNIX, as well as several other operating systems
ü 7is actively being developed
ü encourages user feedback through new ideas, bug reports and patches
Service Profile: HTTPD
ü Type: SystemV-managed service
ü Packages: httpd, httpd-devel, httpd-manual
ü Daemon: /usr/sbin/httpd
ü Portss: 80(http), 443(https)
How does web-server works
- The browser broke the URL into three parts:
- The protocol (“http”)
- The server name (“www.digitalworlditsystem.com”)
- The file name (“index.php”)
- The browser communicated with a name server to translate the server name “www.digitalworlditsystem.com” into an IP address, which it uses to connect to the server machine.
- The browser then formed a connection to the server at that IP address on port 80.
















